Datasets
Datasets can be used via data blocks inside your prompts. Every item in the dataset will be available as "option" (or "variant") similar to the simple text blocks. This would typically (but doesn't have to) be a placeholder for user data that you want to process with your prompt.
For instance, if you are composing a prompt that should determine the sentiment of emails, you could create a dataset with a few sample emails as items to test in the prompt.
Datasets can be shared between different prompts in your project, but not across projects.
Once Endpoints are available, you will be able to pass user data as payload with your request to replace the test data.
How Not to Use Datasets
Promptmetheus datasets are not related to RAG and are not intended for batch evaluation of large amounts of data. Do not load your entire test data into a dataset, 5 to 10 entries are usually sufficient. In the future there will be a dedicated workflow for batch evaluations.
Affixation
The idea behind affixation is to make it easier to mark input data in your prompt. A very common scenario would be to do something like this:
Example
The following is an entry from a micro journal:---
Some entry here...
---
Extract all emotions that are present in the entry based on the following list:
[Anger, Anxiety, Awe, Boredom, Calmness, Cheerfulness, Confusion, Contempt, Curiosity, Desire, Disappointment, Disgust, Embarrassment, Enthusiasm, Envy, ...]
Print only the emotions as a comma-separated list, nothing else:
In this example we use two datasets, one to sample entries and one to test the prompt with different sets of emotions.
To make it easier for the LLM to understand the prompt we use markers (violet) to wrap each dataset (take a look at the "Prompt Engineering Tips & Tricks" post to learn more about markers).
It would be quite annoying to have to add the markers to each dataset item individually and that is where affixation comes in handy.
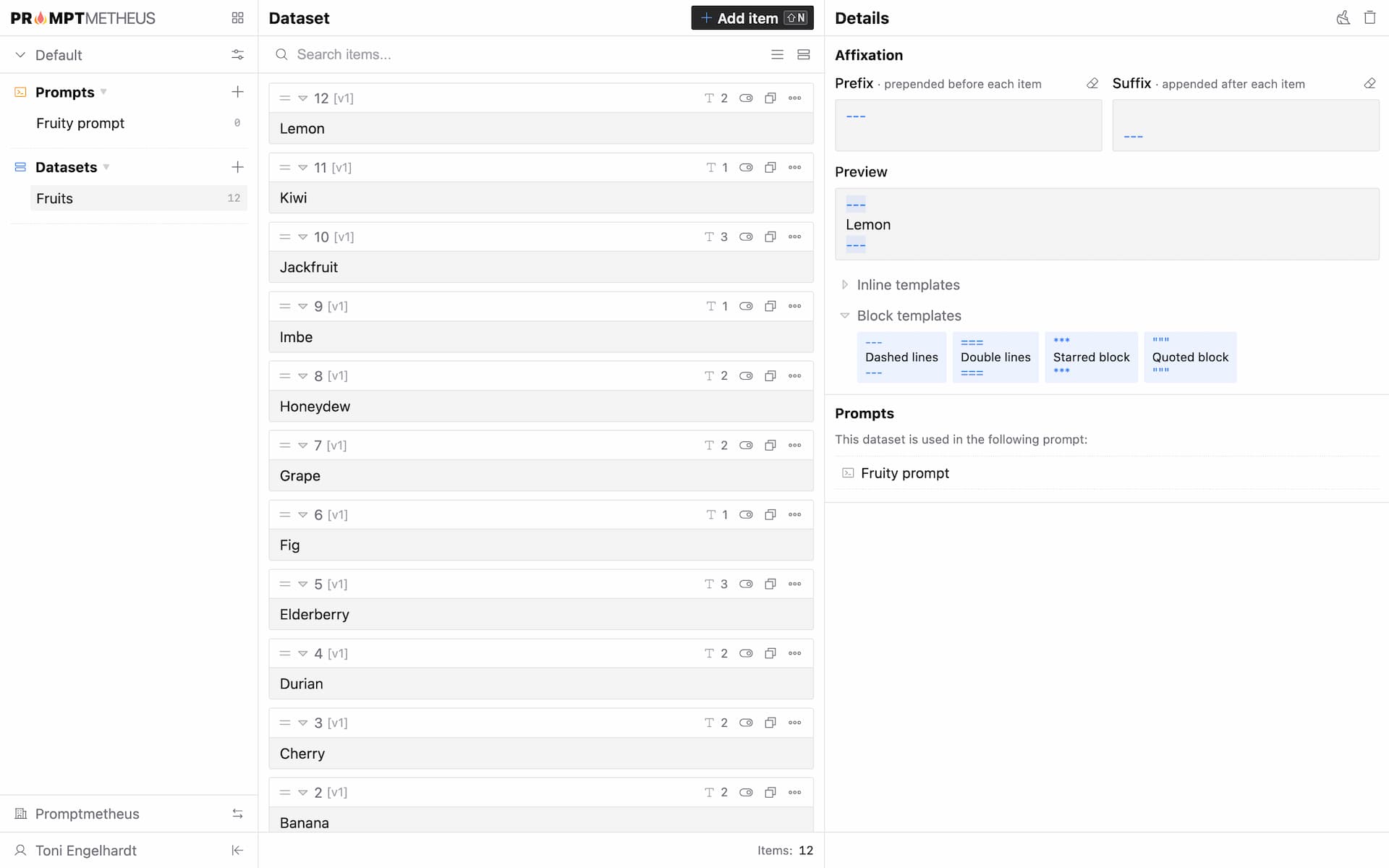
Prefix/Suffix
Promptmetheus allows you to specify a prefix and a suffix for datasets. The prefix will always be prepended to each dataset item and the suffix will always be appended to each dataset item. In prompt views affixation is always highlighted in blue to easily distinguish it from the actual dataset item.
Affixation is recommended for most datasets to make it easier for the model to understand where the data begins and where it ends.
There is no big difference in performance between different affixation styles, it's mostly a matter of taste.
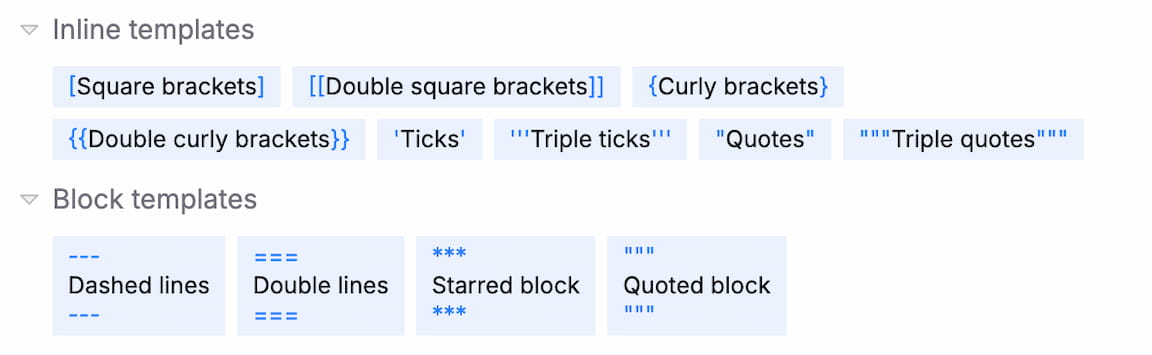
Templates
Promptmetheus provides a few templates (inline and block) to quickly add common affixation to your dataset. To apply a template, just click on it and the prefix/suffix fields will be populated with the respective values.